2012.05.11
This is an update for
my previous
post about the global behaviour of mem_fence() on existing GPUs
for ones which have started existing since then.
On previous AMD architectures the caches were not really used except
for read only images. The latest Tahiti/GCN GPUs have a read/write,
incoherent L1 cache local to a compute unit. Since a single workgroup
will always run on a single compute unit, memory will be consistent in
that group using the cache.
According to the OpenCL specification, global memory is only
guaranteed to be consistent outside of a workgroup, after an execution
barrier, i.e. the kernel is finished, so memory will be consistent
before the next invocation. I found this to be really annoying and
would ruin my kernels, and in some cases had a high overhead from the
multiple kernel launches.
The write does seem to be committed to memory like the IL
documentation would indicate, however the read is still problematic
outside of the workgroup. You must bypass the L1 cache in order to
ensure reading an updated value.
For some cases I found it faster and more convenient to use atomics to
bypass the L1 cache (e.g. read any given int value with
atomic_or(&address, 0)).
Use atomics to bypass the L1 cache if you need strong memory
consistency across workgroups. This is an option for reads that aren't very critical. This was
true for one of the N-body kernels. For another it was many times
slower than running a single workgroup at time to ensure global
consistency.
In the future when the GDS hardware becomes available as an extension,
it will probably be a better option for global synchronization. It's
been in the hardware at least since Cayman (and maybe Evergreen?) but
we don't (yet) have a way to access it from the OpenCL layer. On the Nvidia side, there is the potential that mem_fence() will stop
providing a truly global fence in a future compiler update. Since CUDA
4.0 or so the OpenCL compiler has supported inline PTX. You can get
the same effect as __threadfence() by using the membar.gl instruction directly:
inline void strong_global_mem_fence_ptx()
{
asm("{\n\t"
"membar.gl;\n\t"
"}\n\t"
);
}
2011.08.04
Update: This information is only partially useful on the most recent Tahiti/GCN GPUs, and a safer option is now available for Nvidia
I've been working on the Milkyway Nbody GPU application using OpenCL, mostly basing it off of
a CUDA implementation of the Barnes-Hut algorithm. The port (and addition of a slew of other minor features and details to match the original) to OpenCL has been quite a bit more painful and time consuming than I anticipated. In it's current state, it seems to work correctly on Nvidia GPUs (somewhat unsurprisingly).
The most recent problems I've been exploring is an apparent "tree incest" problem which seems to happen quite frequently in situations where it should not. In the traversal of the tree to compute a force on a body, it should enter nearby cells and perform a more accurate force calculation based on individual bodies (as opposed to the center of mass of a collection of farther away bodies, which is how this is an O(n log n) approximation and not the basic O(n2) algorithm. Logically, the cell a body itself belongs to should be entered and forces calculated from it's neighbors while skipping an interaction on itself. If when calculating forces on a body it doesn't run into itself, there's something wrong. This can happen ordinarily depending on the distribution of bodies, usually when bodies are very close to the edges of a cell. It happens most often with the classic cell opening criterion, particularly when using opening angles close to the maximum of 1.0. This is happening nondeterministically and in all cases on AMD GPUs (usually for some small number of bodies relative to the total I'm testing with), so something is slightly broken.
The CUDA implementation uses in several places the __threadfence() and __threadfence_block() functions. The CUDA documentation for these functions is mostly clear. It stalls the current thread until its memory accesses complete. The closest equivalents in OpenCL are the mem_fence() functions. According to the AMD porting CUDA guide says of __threadfence() that there is "no direct equivalent" in OpenCL, but that mem_fence(CLK_GLOBAL_MEM_FENCE | CLK_LOCAL_MEM_FENCE) is an equivalent of __threadfence_block(). My guess was that the potentially different behaviour between mem_fence() and __threadfence() might be responsible, so I went looking for what actually happens.
Ignoring the supposedly identical __threadfence_block(), and mem_fence(GLOBAL|LOCAL) I went looking at __threadfence().
According to the CUDA documentation
__threadfence() waits until all global and shared memory accesses made by the calling thread prior to __threadfence() are visible to:
- All threads in the thread block for shared memory accesses
- All threads in the device for global memory accesses
According to the OpenCL spec, a mem_fence() "Orders loads and stores of a work-item executing a kernel. This means that loads and stores preceding the mem_fence will be committed to memory before any loads and stores following the mem_fence." Earlier in the spec (section 3.3.1 Memory Consistency), it states that "Global memory is consistent across work-items in a single work-group at a work-group barrier, but there are no guarantees of memory consistency between different work-groups executing a kernel." This says that there's no concept of (device) global memory consistency. The global memory accesses are completed and visible to other threads in the same workgroup and only at a barrier, which this is not. I guess that means the writes could be trapped in some kind of cache and only visible to threads in the other wavefronts executing on the same compute unit making up the workgroup. This is quite the difference from the much stronger __threadfence() where the writes are visible to all threads in the device. From this it unfortunately sounds like what I need to happen can't be done without some unfortunate hackery involving atomics or splitting into multiple kernels to achieve a global weak sort of "synchronization." Breaking (some of) these pieces into separate kernels isn't really practical in this case. It would have been kind of painful to do and slower. I figured I would look into what actually is happening. Since things seemed to be working correctly on Nvidia, I checked what happens there. Inspecting the PTX from CUDA and my sample OpenCL kernels, it appears that the CUDA __threadfence() and __threadfence_block() compile into the same instructions as OpenCL's mem_fence() (as well as read_mem_fence() and write_mem_fence()) with the different flags. Any of the fences with a CLK_GLOBAL_MEM_FENCE compiles to membar.gl, and mem_fences with only CLK_LOCAL_MEM_FENCE compiles to membar.cta. I thought the PTX documentation was more clear on what actually happens here. According the PTX documentation, membar.cta "waits for prior memory accesses to complete relative to other threads in the CTA." CTA stands for "Cooperative Thread Array," which apparently is a CUDA block (an OpenCL workgroup). This would seem to confirm the same behaviour with mem_fence(LOCAL). More interestingly, membar.gl waits for prior memory accesses to complete relative to other threads in the device confirming that __threadfence() and mem_fence(GLOBAL) have the same behaviour on Nvidia. If the problem I'm debugging is this issue, this explains why it does work as expected on Nvidia. Since now I was sure the correct thing should in fact be happening on Nvidia, I checked the AMD IL from my sample kernels, and found fence_lds_memory in the places I was most interested in. AMD IL instructions are built up out of a base name (in this case "fence") and then have modifiers prefixed with underscores appended to the name. In this case, the _lds modifier is the local fence around the workgroup. The LDS is the "local data share," and is the same as OpenCL __local memory. Once again, mem_fence(GLOBAL|LOCAL) appears to have the same expected behaviour as __threadfence_block() as expected. Specifically, it states that:
_lds - shared memory fence. It ensures that:
- no LDS read/write instructions can be re-ordered or moved across this fence instruction.
- all LDS write instructions are complete (the data has been written to LDS memory, not in
internal buffers) and visible to other threads.
What I'm actually looking for is the global behaviour, as given by the _memory modifier:
_memory - global/scatter memory fence. It ensures that:
- No memory import/export instructions can be re-ordered or moved across this fence instruction.
- All memory export instructions are complete (the data has been written to physical memory, not in the cache) and is visible to other threads.
I supposed I should also have checked the final ISA to be sure, but I'm lazy and gave up on finding the Cayman ISA reference. Tthere does appear to be some sort of waiting for the write:
03 MEM_RAT_CACHELESS_STORE_DWORD__NI_ACK: RAT(11)[R0].xy__, R1, ARRAY_SIZE(4) MARK VPM
04 WAIT_ACK: Outstanding_acks <= 0
I guess this might kill my hypothesis about the different mem_fence() behaviour. I would feel a bit better if it included the phrase "in the device" at the end, but my reading of this is still that it does what I hoped. It does appear that a mem_fence() is consistent across the device with AMD and Nvidia's GPU implementations of OpenCL, so now I need to do more work to find what's actually broken. So now I'm relying on implementation detail behaviour beyond the spec (it's not the only place...), but oh well. It's much nicer than the alternative (more work). The conclusion of all of this, is that relying on OpenCL implementation behaviour, a mem_fence() with CLK_GLOBAL_MEM_FENCE should work among all threads in the device for both Nvidia and AMD GPUs (at least on current hardware) and as far as I can tell from chasing the documentation.
2011.04.01
Milkyway@Home has now been released for iPhone / iOS! Now you can not only use your GPU to figure out the structure of our galaxy, but your phone too!
You can get install instructions on the news post.
Technically, the new client is only semi-functional. The actual important core code is there and working, but the BOINC pieces are missing which are necessary for it to be to more (sort of) useful. It downloads 1 of about 5 sample workunits (which also happen to be 1000x smaller than the real versions so that they actually can complete on the phone). Checkpointing and some other stuff still works normally. There wasn't really time to port BOINC / the libraries, so there isn't any accounting or actual task fetching. The results also are just optionally emailed to me at Milkyway4iOS@gmail.com. I'm curious what results I'll get back.
The small tests that run in about 10 seconds on my desktop take over 20 minutes on my iPhone 3g, and drain the battery about 8%, so it's about 2 orders of magnitude slower. I do not think the full size units will complete in a week, although I haven't actually tried it.
2011.03.25
I've just finished making the next release of the Milkyway@Home N-body
simulation. These should start going out soon along with new
searches. The major change in this version is that Lua
is now used for configuration instead of the old static JSON file. You can now script
a totally arbitrary initial particle distribution, and you can run a
simulation without the milkyway background potential, so it's probably
more useful for anyone else to use now for other N-body
simulations.
This all started one night when I was planning on finishing the few
remaining issues with the new CAL/CAL++/ATI Separation application,
but needed to get some reference results from the working OpenCL
application on Nvidia. But then Tim
Horton left Jayne (the system with the GTX 480 donated by a Milkyway@Home
user) running Windows and disappeared somewhere. Then there was
something of an obstacle to doing what I was planning on doing and I
thought it would be cool to have an embedded dynamic language. My
original thought was to use JavaScript after Seed, but JavaScriptCore isn't
really split out from Webkit, and the full Webkit dependency was too
much for what I needed. I considered Python, but the Lua libraries
were an order of magnitude smaller, so I chose it and spent the next
few days getting basic things working. I spent a long time writing
boring bindings for many of the structs for the N-body simulation. I
later found that if I had used LuaJIT, it seems it would have done
most of the work for me. About a week later I had something working.
Although the mini-API isn't really close to what I originally
envisioned or wanted, you can now script any simulation you want. I'm
considering making it possible to use a Lua closure for the external
potential, but I'm not sure how much slower that will be.
This enables more complex models to be fit without a need to make new
releases, and avoids a need to mangle the code every time the model
changes to support more combinations of features. The current plan is
to try multi-component dwarfs, with an extra component of dark matter
which will be ignored in the final likelihood calculation.
I've fixed a few other small random bugs, such as in some cases on
Windows some system IO error would happen when checkpointing, and
there would be a "something something failed: No error" type error
message. I'm also using newer BOINC libraries for Linux to hopefully
avoid the
random crashes which were coming from the 6.10.58 libraries.
I've switched to only using the multithreaded versions using OpenMP
for all systems. The 64-bit Windows build is now actually 64 bit as
well. Building on Windows is still an agonizing process (mostly
getting dependencies and a functioning build environment, not actually
building it) I don't understand, but it's getting better.
You can download the source here.
2011.02.19
Today I fixed the most time consuming bug ever. I believe I've spent
well over 50 hours total actively trying to find it, and countless
more thinking about it. I first encountered this problem some time in
early December on my first pass through the new CAL/CAL++ for ATI
GPUs Milkyway@Home
separation application. The final results were differed on the order
of 10⁻⁶, much larger than the required accuracy within
10⁻¹². I took a long break in December and early
January to apply to grad school and other things, but I was still
thinking of the problem. Nearly all the time I've spent working on
Milkyway@Home since I got back to RPI almost a month ago has been
trying to find this bug. It's stolen dozens of hours from me, but it's
finally working.
The problem was errors that looked like this:
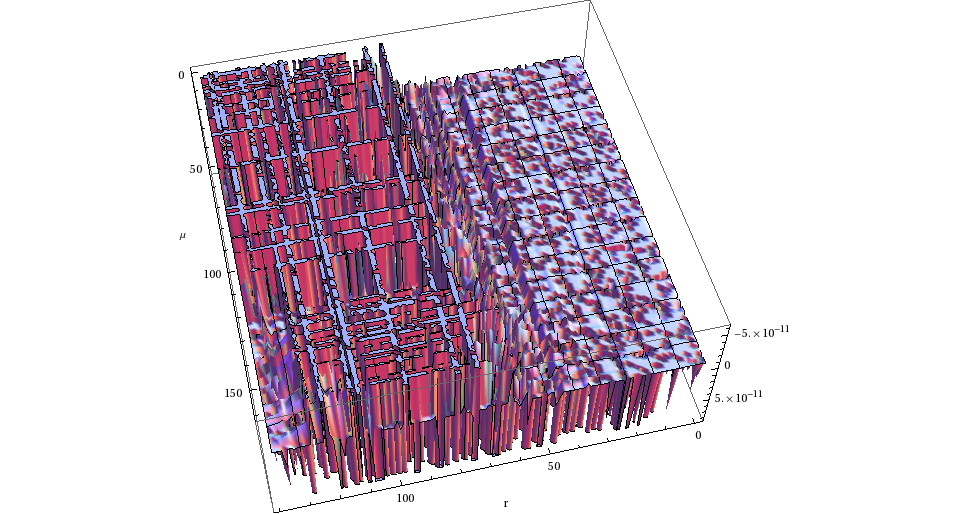
This is the μ · r area integrated over one ν step in the integral
from the broken CAL version compared to the correct OpenCL results.
It looks like there's almost a sort of order to the error, with the
grids and deep lines at some points, though the grids are much less
prominent when the full range of errors are plotted, except for the
deep line in the middle of r. I spent many hours looking for something
related to reading/writing invalid positions in the various buffers
used (I find dealing with image pitch and stuff very annoying), and
every time finding that everything was right after many hours of
tedious work comparing numbers.
It also didn't help that for a long time, my test inputs were not what
I thought they were, which finally pushed me to get the automated
testing I've meant to get working since I started working on the
project last May.
I eventually happened to find this
this on the internet.
I vaguely remember finding this before and reading "Declaring data
buffers which contain IEEE double-precision floating point values as
CAL_DOUBLE_1 or CAL_DOUBLE_2 would also prevent any issues with
current AMD GPUs." and decided whatever changes it was talking about
didn't apply to me, since I was already using the latest stuff and
using the Radeon 5870. Apparently this is wrong.
This claims CAL_FORMAT_DOUBLE_2 should work correctly, but it
apparently doesn't. I also don't understand why I can't use the
integer formats for stuff put into constant buffers. I spent way too
much of my time searching for random details in ATI
documentation. It's rather annoying. Switching to the
CAL_FORMAT_UNSIGNED_INT32_{2 | 4} formats
for my buffers solved the stupid problem. I guess some kind of
terrible sampling was going on? I don't understand how that results in
the error plots, with half the buffer being much worse, and the grids.
I really don't understand why this wasn't in the actual documentation,
and instead I just happened to find this. Only one of the provided
examples for CAL uses doubles, and it is a very simple example.
2011.02.09
I'm posting these so I don't accidentally almost lose them again, since it's rather painful to make them again, and in the unlikely event they're actually useful for someone else.
I have binaries for the Milkyway@Home dependencies, in particular popt built with Visual Studio (which I ported last semester, which mostly involved removing C99 features, and casting mallocs since MSVC brings in lots of C++ stupidity to C while somehow also not supporting C99 features that are in C++).
For MinGW libraries, the BOINC libraries are 6.10.58 with my patch to fix the MinGW build from last June, which still hasn't been applied.
Crlibm, as required by the N-body to get consistent math results, I never got to truly work on Windows. These have the crlibm_init() function stripped out, since headers it was using to set the x87 FPU control flags seemed to be missing. It's been on my TODO list to get Crlibm properly working on Windows (and maybe with MSVC too), but I haven't gotten to it.
These are binaries for MSVC 2010, and for MinGW with GCC 4.4 (from TakeoffGW), for use with the static runtime (/MT). I had some trouble recently when trying to link these with GCC 4.5 stuff (at least the BOINC/C++ parts since C++ linking tends to stop working with new releases of things) from the new MinGW installer, so I'm not sure it will work with those.
MinGW dependencies
MSVC dependencies
Popt built with Visual Studio
2011.01.10
The evening started out with a simple goal: to avoid paying extra for
an Apple approved video card, and get more screens to work for
Peter. For his Mac Pro, Peter made the unfortunate choice of a Radeon
5750, as this GPU does not have doubles. Doubles are a critical
feature for
Milkyway@Home. Apple's OpenCL implementation unfortunately seems to be missing support for doubles
on GPUs which is also problematic.
We started out leaving
Open Source Software Practice class and headed to Peter's
apartment, stopping for pizza on the way. Peter gave us a tour of his
scary apartment in the sketchy parts of Troy, and showed us the demon
GPU. Tim and Peter argued for a while about something dealing with
backups and new hard drives. Earlier Tim had been giving out hard
drives after giving up on Jayne's disk situation and getting a new NAS
box, in addition to random sale drives Peter had. Peter was concerned
about preserving his torrents; his ratio is important to him. There
was some kind of copy that was never going to finish.
To use this random GPU from Newegg in the Mac Pro, it needed new EFI
friendly firmware or something like that. It's not exactly clear to me
why it needs to be different. I had suggested to Peter getting the
5830, since the 5830 a much more acceptable card, with doubles! I
found a comment on a blog post about these hacky firmwares which
claimed to have it sort of working with some weird caveats about which
outputs worked. The correct, good GPU with no work would be a 5870
from Apple, though that would be more expensive.
We sat around Peter's apartment for a while before heading to our
apartment to use my desktop for flashing purposes. Peter drove us, but
there wasn't parking near our apartment. We went one street over, a
strange place I have never been before. I have had to swap my GPU on a
daily basis recently to work on Milkyway@Home, so I put in Peter's new
GPU. While waiting to be told the next step to try, I played with the
AMD OpenCL examples. To flash the video card, we thought we needed to
get a DOS boot disk with the flash utility, which couldn't be used
from Windows. It turns out this is close to impossible. I don't really
remember all the nonsense we tried, but there was all kinds of boot
sector hackery, and 16-bit tools which wouldn't run. We spent many
hours making various disks and trying to flash with each one. Files
would just mysteriously not show up and pretty much everything was
failing. While the garbage utilities we were trying to use were old,
the whole experience seemed like an adventure in computer use from the
very early 90s. We booted off of Tim's camera, although it didn't
actually help.
We eventually gave up and decided we could try flashing it again after
it was installed in the Mac Pro and see if it would just happen
to work. We went outside and couldn't find Peter's car. We walked up
and down the street looking for it, and Peter came to the conclusion
that it was towed again. It turns out it was; the fence we parked in
front of was apparently a driveway of sorts. The next day Peter was
supposed to drive some person he had never met through some extended
relation, and didn't really want to do it. He now had the perfect
excuse to get out of it, but for some reason was determined to go get
the car now. We didn't have any other way to get there, so we were
going to walk.
We stopped at the pizza place briefly so Peter could get money for the
tow from the ATM. We then started our walking adventure through Troy
after midnight. I haven't really wandered through Troy yet in almost 4
years. This walking adventure took a bit more than half an hour to the
fabulous garage. Some random people in a car parked there said the guy
was calling back, but Peter still called the guy, who confirmed he was
coming back. We headed around back to where the cars were and paid the
tow guy, where some kind of sketchy guy showed up behind.
Peter paid $200 I think for the tow. It would have been cheaper to buy
the Apple 5870 in the first place and avoid all of this. After that,
we went to Denny's. Peter had commentary on some of the other patrons
here at 2 am. I noticed that many of the people were old and wearing
fancy clothes which I found strange.
I ordered some kind of food which I didn't quite understand what it
was, so I pointed to it on the menu using my formidable social
skills. I didn't quite get the right thing, but close enough. While
sitting there eating, Peter explained that he had talked to Netkas
about something or other related to the original GPU problem. Tim and
I got excited, and sort of asked in disbelief about this conversation
with him. It was kind of sad and hilarious that we both instantly
recognized this completely random OSx86 hacker. We left Denny's and
still didn't have a working GPU in a Mac Pro so everything was a
complete failure.
2010.05.13
I've mostly spent the semester doing homework; I didn't make as
much progress on Clutterhs as I had planned. I hope once that I'm done
with finals, I'll have time to make the various changes I want and
finish binding Clutter 1.2. The release of Clutter 0.2 is still
waiting on those, as well as a release of
gtk2hs.
In total, I've completed 58 physics homework assignments, 3 essays, 6
tests, a large number of class exercises and quizzes, and 3 upcoming
finals. I've spent countless hours doing nothing but math. On
occasion, there was lots of help from
Mathematica.
In the 3 physics classes I took this semester (Electromagnetic Theory,
Intro to Quantum Mechanics, Thermodynamics and Statistical Mechanics),
in total I did 315 pages of LaTeX/
Lyx
homework at an average length of
5.4 pages each. Nearly all of that being just
math, with an
occasional graph
or chart. This is in addition to the countless scraps of paper I
occasionally used (although as time passes I find myself just doing
nearly all of the simple algebra in my head and entering directly into
Lyx.)
I'm rather disappointed to not be going anywhere this summer. I
applied to over a dozen different research programs for the summer for
physics and astronomy at a wide array of random places; I was rejected
from all of them. I finally did get accepted to work on
milkyway@home, which is what I'll be working on this summer. I'm
glad to be working on this, although I really don't want to stay in
Troy. It may be my ideal research project.
I accidentally got accepted to GSoC. I applied as a final
fallback in case I didn't get accepted to do research with
milkyway@home. I found out after the GSoC deadline, and some time
before the selected students were announced I dropped out as a
student, at least according to melange. A while later it seems I was
accepted anyway to work on the gobject introspection based binding
generator for gtk2hs. I'll probably end up doing some work on this
over the summer; it might also become what I work on next semester for
RCOS. One of the other rejected
Haskell proposals is now taking my place.
2010.05.07
One of the primary features of this blog from near the beginning was
the addition of the
Cornify
button, currently at the top of the page. It makes unicorns
happen. Last weekend at
ROFLCon
I had this picture taken of me with a unicorn, and with the guy who made
Cornify right behind me wearing a unicorn shirt.

Unicorns are pretty cool.
2009.11.29
I've made an early release of Clutterhs, and it's on Hackage. There's still a fair number of things that don't work yet, and lots of messy code that needs to be cleaned up, but most of the core stuff should work. There isn't a tutorial yet, but overall usage is similar to gtk2hs. If you want to try it, the best thing to do would be to look at the simple demos in the git repo. They aren't very good examples, and just sort of use a bunch of random stuff but they should help with the general idea of how to use it (which is still quite likely to change).
|
